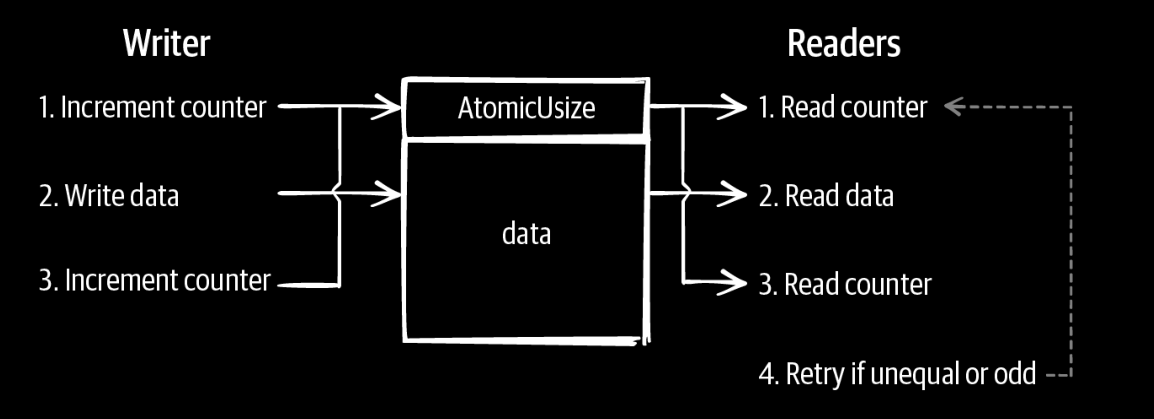
basic of rust concurrency
内部可变性是指可以通一个不可变引用来实现对内部数据的修改。标准库中有Cell<T>,Cell相当于持有这个Obj,要做修改只能先把T move出来再把T塞回去。RefCell<T>不但持有这个obj,还会维护一个引用计数,如果在运行时有多个Mut借用时,会panic。RwLock是多线程版本的RefCell,但是多个可变借用时,或者说多个写时,会block住试图拿这个可变借用的线程,让它进入sleep。而Mutex不像Rwlock可以实现多个可读借用,mutex是彻底的独占的,其它线程都必须等待锁的释放。UnSafeCell是实现内部可变性的关键类型,它只有get函数可以得到一个底层类型的raw pointer,UnsafeCell没有任何保证安全性的限制,需要用户自己来进行安全性的保证。一般不会直接用unsafe cell,都是包装成另一个类型来限制使用,比如实现成cell或者mutex。Sendtrait意味着这个类型的所有权可以在线程之间转移,Synctrait意味着这个类型可以在线程之间共享。
一个struct如果所有的类型都是send和sync,那它本身也是send和sync的,如果要实现非send和sync的话,可以用phontomdata 标记类型。PhantomData用于标记Struct非sync,毕竟这是个zero sized type。
给一些非auto trait实现send和sync是unsafe的,因为取决于其中类型的具体实现,所以安全性需要自己来保证。
rust的mutex,实现了一个其它线程如果持有了mutex,但是panic了,这个mutex就是poison的机制:rust mutex doc。
mutex一些值得注意的点:
if let的scope。
if let Some(item) = list.lock().unwrap().pop() {//会lock到这个if结束 process_item(item); } if list.lock().unwrap().pop() == Some(1) {//在进入body前,MutxGuard就已经drop掉了。 do_something(); }rust 2024做出的一个if let的小修改,即if let的表达式生命周期不会延长到else body中去:rust 2024 doc
大多数的读写锁的实现都会block新的读者出现,当写者等待时,因为可能会多个读者共享导致写者一直要等待,这是读写锁中一个经典的饥饿问题。 ## parking and condition variables 当一个线程在等待别的线程的通知的时候,这种叫thread parking,parking的时候,线程会进入睡眠,唤醒可以用unpark。 在实现上,unpark有一个很重要的特性是,有一个信号保留机制,即unpark在park之前执行了,这个park也不会让线程进入睡眠,因为消费者需要对生产者的每一个unpark都有响应,否则会有丢数据的风险。 但是unpark并不能叠加,所以unpark两次后,再Park两次还是会线程进入睡眠。
条件变量一般是与mutex结合使用,传入同一个mutex,一个线程wait,一个线程notify。如果两个线程在操作同一个条件变量但是不同的mutex,会引起panic.
Atomic and Memory order
原子类型可以在多线程间安全的访问和修改,但是依赖于Memory Ordering。比如最简单的order,Ralex,Relax只能保证单个变量的一致性,而多个变量间顺序无法保证。 atomic i32的溢出是回环的,不像普通的i32,溢出是会panic的。 为什么需要memory order?CPU会为了优化而把程序中的指令进行重排,写的是什么顺序,执行起来可能是别的顺序。 Happens before即保证A发生在B之前,但是在多线程中却是不一定的,使用锁可以保证,或者更严格的memory ordering。
Relax
Relaxed Ordering保证了单个atomic变量的总修改顺序.
Relaase and Acquire
Release与Acquire是成对使用,release给store,acquire给load。acquire-load可以观测到所有的release-store的操作,可以保证所有的store都会发生在load之前。同时,还有一个两者的结合体,即AcqRel。
consume
只能说,load发生的时候,取决于这个值的读取操作,只能说store肯定发生于相关表达式求值这前,而非相关的肯定不会。但是实际上所有的CPU都是实现为relax,而编译器根本不支持这个操作。不会保证全局顺序的一致性。
SeqCst
SeqCst保证了所有的acquire ordering与release ordering,也保证了全局操作顺序的一致性。如果在乎性能可以使用 seqcst fence与relaxed ordering来代替。
实际上release store可以分解成fence与relaxed ordering,因为fence会导致同步:

所有的store在release fence后面 会被acquire fence之前被观测到,即同步
Understanding the processor
在x86和arm下,最低要求的Relaxed的load和store,与普通变量的读取与写入是一样的。(我觉得主要原因是x86是TSO,远大于Relaxed的同步要求,而arm这是默认最低水平的同步要求。)
但是如果是Read-Modify-Write这样的顺序的话,比如*x+=1,这样的语句,对于x86来说,只有一条mov,这样是原子的,但是对于arm来说,这是三条指令,这意味着它并不是原子的了。
普通的add并不是原子的,因为在cpu看到会拆成好多条微指令,所以并不是原子的,如果要实现原子性的add或者其它操作,需要用到x86下的lock 前缀。
在x86下,add,sub,and not or xor都支持lock前缀,当它们加上了lock前缀之后,会block住其它核心 ,之后会将结果同步给其它核心,以完成同步。
只有add有xadd指针,x意味首exchange;对于bit,可以用bts,btr,btc指令来实现,这些指令也可以加lock。
而compare and exchange有cmpxchg 指令,可以实现比较然后交换。
load-linked and store-conditinal instructions
对于RISC架构来说,LL/SC loop是最接近cmp and exchange语义的。其中包含了两个基本指令,一个load,一个store-conditional。与普通的load store不一样的是,如果在store的时候,有其它线程在load-link指令后写入内存,store会拒绝写入。 用这两个指令,可以实现读取,修改,写入,如果中间因为别的线程有修改写入失败了,则重试即可。 在x86用fetch等指令,可以生成与compare and exchange相同的指令,但是在arm上并不一定,这种优化实际上很难做,因为ll store中间能插的指令过少
cache
MESI的四个状态,modified:包含了本cach line修改了但是没有写回主存的数据,exclusive:只有本cache line有的数据,Shared:包含与别的cache 一样的数据,没有修改的数据,invalid:指cache line空的,或者dropped,意味着它没有任何有效数据。 对于多核CPU来着,cache 的状态变化会在这四个状态间切换,比如一个核心独占的cache,如果别的核心也需要的话,状态就会变成共享的。 另外也有一些变种的协议,加上一些别的状态,比如修改过的cache并不马上写回到下一个level中,而是同样可以共享。
对性能的影响
use std::{hint::black_box, sync::atomic::AtomicU32, sync::atomic::Ordering::*, time::Instant};
static A: AtomicU32 = AtomicU32::new(0);
fn main() {
black_box(&A);
std::thread::spawn(|| loop {
black_box(A.store(1, Relaxed));
});
let start = Instant::now();
for _ in 0..1_000_000_000 {
black_box(A.load(Relaxed));
}
println!("time is:{:?}", start.elapsed());
}
这段代码,如果store改成load,那么cache line的同步的开销几乎可以不计,对多线程的load没有什么影响,但是如果是store,会有很大同步的开销的,在我的老笔记本上,这个执行时间从11秒变到了40秒(不是,我的笔记本也太差了,书中写的是现在的新x86CPU从200ms变成600ms)。
原因是store的话,需要独占整个cache line,并且要写回到下一层,再被其它线程去load。如果把指令改成cmp & echg,也是一样的,因为无论cmp失败与否,它都需要独占cache line。
如果是多个变量在同一条cache line上,对于这些变量的操作也会受到cache一致性的影响,性能会有所下降,最好是把不同的变量分到不同的cache line上。
static A: [AtomicU32;3] = [AtomicU32::new(0),AtomicU32::new(0),AtomicU32::new(0)];
fn main() {
black_box(&A);
std::thread::spawn(|| loop {
black_box(A[0].store(1, Relaxed));
black_box(A[2].store(1, Relaxed));
});
let start = Instant::now();
for _ in 0..1_000_000_000 {
black_box(A[1].load(Relaxed));
}
println!("time is:{:?}", start.elapsed());
}
输出结果
time is: 38.1021
而改进方法是,对变量填充padding,让它占满整个cache line,这样就会互不影响了。
#[repr(align(64))]
struct Aligned(AtomicU32);
static A: [Aligned;3] = [Aligned(AtomicU32::new(0)),Aligned(AtomicU32::new(0)),Aligned(AtomicU32::new(0))];
fn main() {
black_box(&A);
std::thread::spawn(|| loop {
black_box(A[0].0.store(1, Relaxed));
black_box(A[2].0.store(1, Relaxed));
});
let start = Instant::now();
for _ in 0..1_000_000_000 {
black_box(A[1].0.load(Relaxed));
}
println!("time is:{:?}", start.elapsed());
}
输出为time is 11.12121,可见影响是非常大的。
Reordering
指令重排不仅会发生在编译器生成的时候,而且也会发生指令乱序执行的情况。在现代CPU中,存在一些优化性能的机制,会导致指令的乱序执行。
store buffer
CPU对cache的操作可能先存入store buffer中,然后先去执行别的指令,对于别的线程来说,可能要等store buffer写入了cache后,再通过MESI同步过去。
invaliation queue
同样对于缓存的失效也并不是马上落到cache中,而是先放入一个invaliation queue中,之后再进行失效操作,如果别的核心需要等待这个操作才能执行,那么会在queue写入到cache后才会执行。
pipeline
现代CPU的流水线是高度并行执行指令的,在CPU中会分析指令间的依赖关系,然后同时发射,但是对于编译生成的指令来着,却是乱序的。
对于store buffer导致的指令重排,可以使用内存屏障来保证写操作一定在读操作之前。
Memory ordering
在现代语言中,如果指定了内存模型的话,那么编译器会生成正确的指令,不会生成打破内存模型的重排指令。但是比如non-atomic操作与relaxed模型,重排是可以接收的,换句话说,重排与否与操作和内存模型有关系。 对于内存屏障来说,所有的acquire之后的操作都不能重排在acquire之前,而release之后的操作都不能重排到release之前。 对于GPU来说,复杂的缓存设计与内存设计可能会导致core1的操作与core2的操作在core3看来并不是按core1 core2约定的顺序执行的。而x86与arm,一个核心的操作对于其它核心是可见的,即保证了在其它核心看来也是同一样的顺序,这样数据不同步的问题在这两个架构来看,是能退化成指令重排的问题。arm用的是weakly ordering,可以允许可能的重排,而x86是strong ordering,对于指令重排有严格的限制。
在x86上,保证了store-store的连续性,即store a与store一定是按写下的顺序写下的,同理load a与load b也是一样。唯一允许的重排是store after load,这指的是core1有load a 后面跟了一个store b操作,而core2可以通过store buffer forwarding等优化技术来先load b,这样观察顺序看来就是core1: load a->store b->load b->store-a,core2: load-a load-b store a store b,这样的顺序,而实际执行顺序是没有变的。
在x86上,可以说得到了免费的acquire-release语义的保障,可以说与relaxed模型一样的开销,因为non-atomic操作与atomic操作生成的汇编是一样的,除了SeqCst,要保证全局一致性需要把store改成xexchg,因为普通的store会可能重排。 可以说,在性能上只有store在不同内存序下有性能差异,而其它的load等操作在seqcst和relaxed操作下是没有差异的。
在arm上,因为弱内存序,所有的指令都有可能发生重排。所以加上强内存序后,会生成强内存序的指令,可以保证一致性。而且acq-rel与seq-cst生成的代码是一样的。
对于fence来说,在x86上,只有SeqCst下,才会生成mfence的指令,而在arm上都会生成dms的指令用于等待load store完成,并且防止指令重排。

Operating system interface
在不同系统上,Rust基本上都通过libc去做syscall来完成与系统内核的交互:
* linux上,syscall abi是稳定的,也可以通过汇编下的syscall来实现syscall,虽然这样更快,但是丧失了一些方便性。
* macos上,syscall abi不是稳定的,所以一般都是使用libc提供的posix接口来实现syscall。
* 在windows上也有kernel32.dll来提供syscall。
posix
posix标准下,有pthread作为线程库与同步原语:
* pthread_mutex_t: 创建mutex为pthread_mutex_init,退出pthread_mutex_destroy,可以在init在时候传入attr参数来指定一些属性,一个比较重要的属性是重入性,默认情况下PTHREAD_MUTEX_DEFAULT 是不能重入,可以配置成PTHREAD_MTUEX_ERRCHECK用于报错,配置成PTHEAD_MUTEX_NORMAL会死锁,配置成PTHREAD_MUTEX_RECURSIVE 后mutex即是可重入的。同样还有pthread_mutex_timelock用于有限时间的加锁
* pthread_rwlock_t:与mutex类似也有同样的函数用于创建,退出,同样的默认初始化是用一个宏PTHREAD_RWLOCK_INITALIZER来初始化,write-lock是不可重入的,会导致死锁。read-loack是可重入的,但是在pthread的实现中,读者的等级与高于写者的,读者一直拿着,写者需要一直等待所有的读者都释放锁。
* pthread_cont_t: 同样与mutex类似,都是有一系列函数用于创建,销毁,值得一说的是限时的cond是可以配置成使用instance时间还是wall clock。
* 还有pthread_barrier_it,pthread_sping_lock_t 和once类型pthread_once_t
在rust中包装pthread
包装的时候,因为pthread都是用的地址,与指针强相关,甚至还会有自引用地址,而rust中语义为move,要做到两者的兼容,一个做法是用box包一层:
pub struct Mutex{
m : Box<UnsafeCell<libc::pthread_mutex_t>>;
}
在1.62之前的mutex是这么实现的。这样的实现也会带来一些问题,比如访问的开销,无法把mutex的一些函数变成const fn。一个更大的问题是,MutexGarud是可以使用std::mem::forget来提前释放掉的,在一个scope里,如果一个lock先lock,然后mutexguard释放掉了,然后lock在没有Unlock的情况下去释放,这种情况是ub。
ps1(虽然文中没有提到后面是版本是怎么实现的,但是我觉得在有futex的情况下,应该都是用的futex来实现的)
ps2:看了一下代码,实现const的方式是用OnceBox包了一层,drop的问题,如果已经lock了要去drop的时候,同样把这个mutex给leak掉。
https://github.com/rust-lang/rust/blob/master/library/std/src/sys/sync/mutex/pthread.rs
linux
在Linux上,mutex是用linux提供的一个syscall来实现的,叫SYS_FUTEX。其中包含两个操作,一个是FUTEX_WAIT,一个是FUTEX_WAKE,wait会让线程睡眠,而wake会唤醒。 用futex实现mutex的核心机制是在用户态使用一个atomic变量来表示是否锁住了,当线程A把变量改成1代表持有锁,线程B再去拿的时候,内核会让线程B进入睡眠,然后放入等待队列中,等待唤醒。但是如果可以拿到锁的话,那么就不用进入内核态,大大减少了开销。 rust上的实现如此:https://github.com/rust-lang/rust/blob/master/library/std/src/sys/sync/mutex/futex.rs。
futex operations
一般fuex函数有两个参数,一个是watch的atomic i32变量,一个是操作。
一些操作如链接:https://www.man7.org/linux/man-pages/man2/futex.2.html
一些值得一提的是requeue,当多个线程排队时,第一个线程拿到了变量后,将其它线程重新入队等待另一个变量的值。
futex_wake(wait)_bitset,通过mask来指定wait wake,不会引起惊群。另外就是用于实现rwlock的时候,可以用不同的bit来代表reader writer。
FUTEX_PRIVATE_FLAG,代表所有对同一个atomic操作的线程都是同一个进程,不会跨进程操作,在调用的时候,所有的调用都得带上这个flag。
优化级相关:当进程优先级高的进程,等待进程优先级低的进程的时候,这叫优先级反转,而futex的做法是,当低优先级线程持有锁时,它会临时继承等待该锁的最高优先级线程的优先级。
对于内核来说,需要futex将atomic变量设置为线程ID,用低30位。用高位来代表解锁与否。
macos
mac用的是pthread实现。但是速度比其它unix平台慢跑,原因是它用的是公平锁,先来先得的机制的。后面10.12才推出了非公平锁。
Windows
windows上的mutex叫critical setion,是可重入的。这个比较重。轻量级的有类似于linux的futex叫WaitOnAdress。还有SRW lock。
其余的同步原语
semaphore
semaphore即OS书中学到的PV操作的同步原语,wait操作会把couter减1,而signal操作会会把couter加1,如果wait遇到counter为0的时候,就会被block住,需要等到signal把counter+1才能唤醒另一个线程。实现上,一个实现是,用一个mutex来保护counter,一个convar来做wait和signal的操作,实现对线程的wait和wake操作。在linux上可以用futex来实现,这样只要用到一个atomic的u32即可实现。
rcu
rcu是一个可以用于大量的数据,多读少写的场景写的无锁数据结构,核心思想是在对一个node做修改的时候,copy一个node出去,让它先修改,其它读者会读到老的数据,然后修改完之后,把node再更新掉:
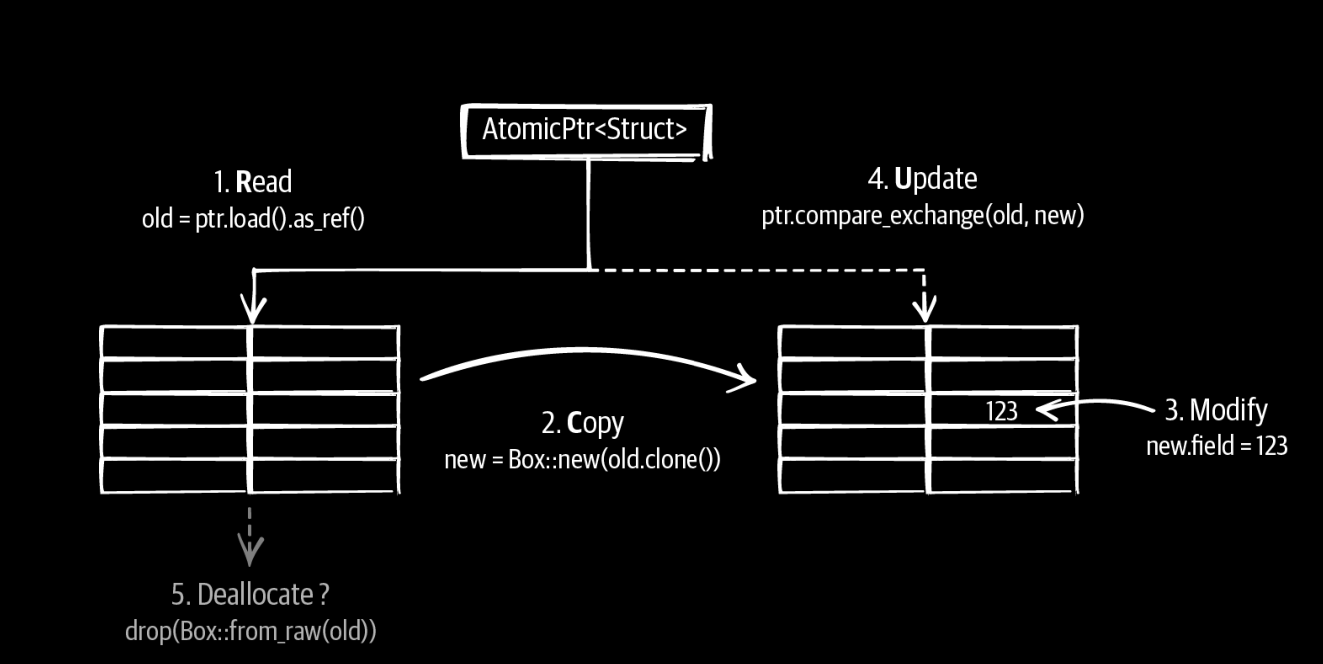
其中最大的问题在于最后一步,如果还有读者在引用老数据的话,需要等所有的读者都不在引用老数据才能释放掉老数据。 linux rcu C++ rcu
无锁链表
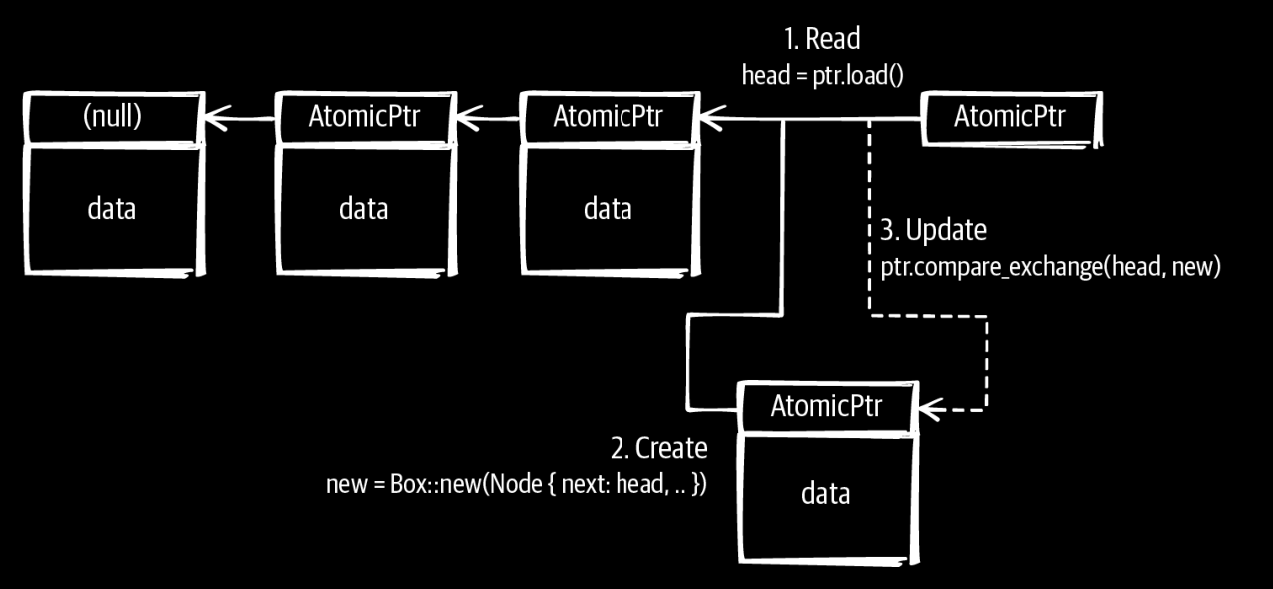
如图所示,这三步操作都可以atomic的完成。值得注意的是,可能会有多个写者来更新插入,要保证只有一个能更新成功。删除一个节点的时候,也有相同的问题,即什么时候才能释放这个节点。可以使用hazerd pointer或者引用计数等技术能实现。 https://lwn.net/Articles/610972/
Queue-Based Locks
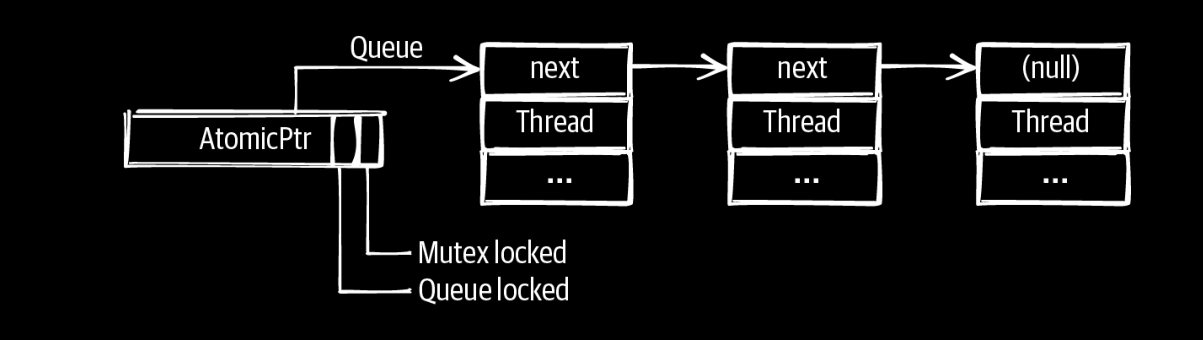
核心思想是,只维护一个atomic pointer,然后指向一个队列,其中指针中没有使用的位,可以用来表示锁的状态。windows里面的slim read write lock就是这么实现的。 ## Parking Lot–Based Locks parking lot 锁是对queue based lock的优化,可以把mutex优化的尽量小,即mutex只用来表示是否有锁,是否有队列,然后另外一个全局变量hashmap来表示,以adress为key,以queue为value。
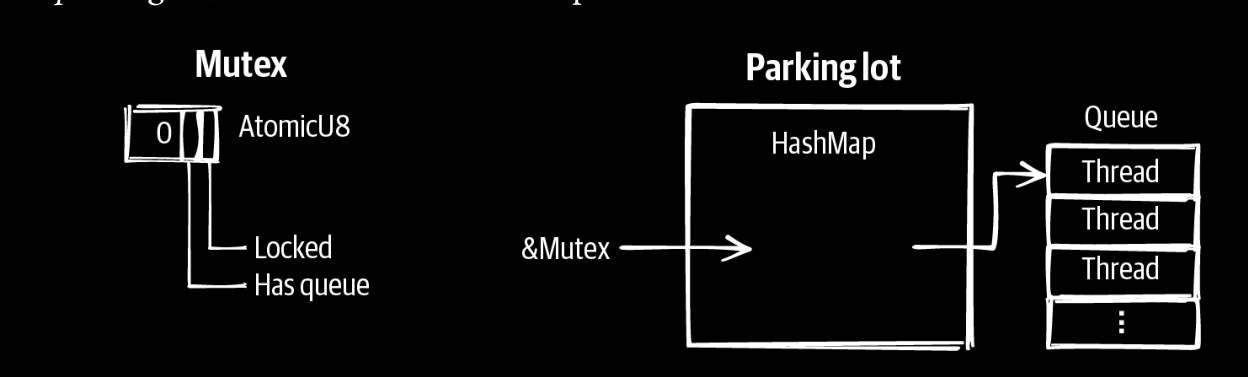
rust中有一个parking_lot就是如此实现的。当然它还有很多优化,优化性能,否则会对hashmpa抢占很严重。
Sequence Lock
Sequence lock的思路是在结构中加上一个counter,当写者进行写的时候,把couter变成奇数,写完之后,再把counter变成偶数,所有的读者都可以随便读数据,但是需要比较前后的couter的数值,如果都是偶数且没有变化,则是有效,否则要重试。